
Figma プラグインを使ってドキュメント内のコンポーネント情報を CSV に出力する場合、数百〜数千レイヤーなら特に問題なく動作します。
しかし、数万〜数十万規模になると処理が固まったり、UI が極端に重くなることがあります。
この記事では「大量のレイヤー規模でも止まらずに CSV を出力できる Figma プラグイン」を実装した方法を紹介します。
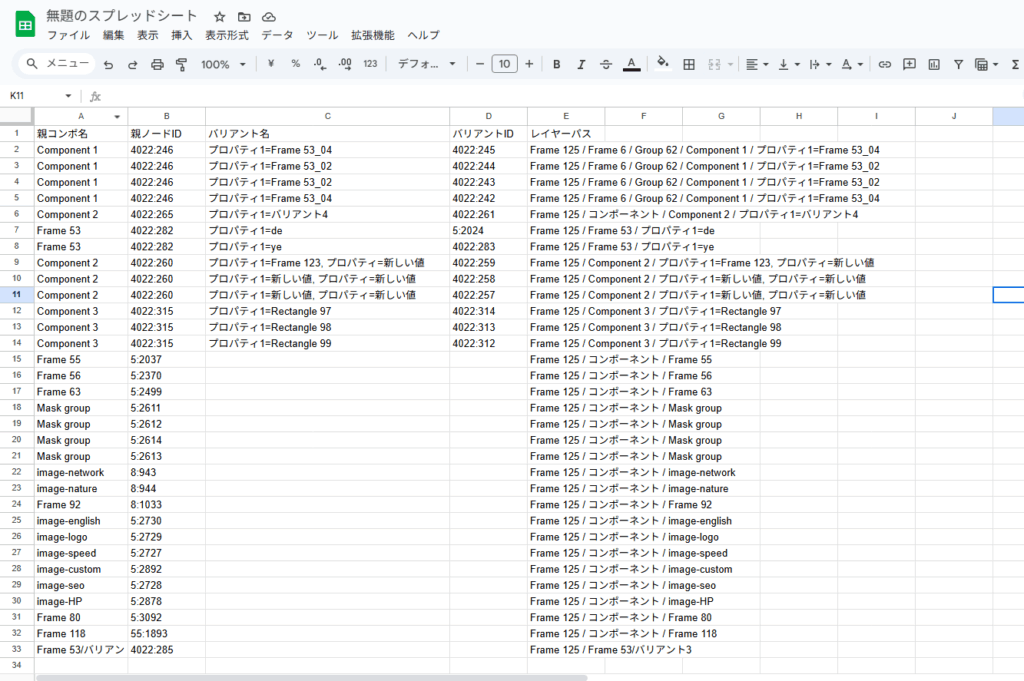
Figmaファイル内にあるすべてのコンポーネント情報を重複なく収集して、CSVに書き出すプラグイン
コンポーネント及びコンポーネントセット(バリアントがあるものはそれぞれ書き出す)ようにしています。
目次
大量のレイヤーを処理するための課題
素直に全レイヤーを走査して配列に詰め、それを一気に UI に渡すと、以下の問題が発生します。
- メインスレッドが長時間ブロックされて Figma が固まる
- UI 側に逐次ログを出しすぎるとブラウザ描画がボトルネックになる
- CSV 文字列をひたすら連結すると、メモリ使用量が急増する
この3つを解決するために、次の工夫を取り入れました。
数十万の大量のレイヤーを一気に処理するプラグイン
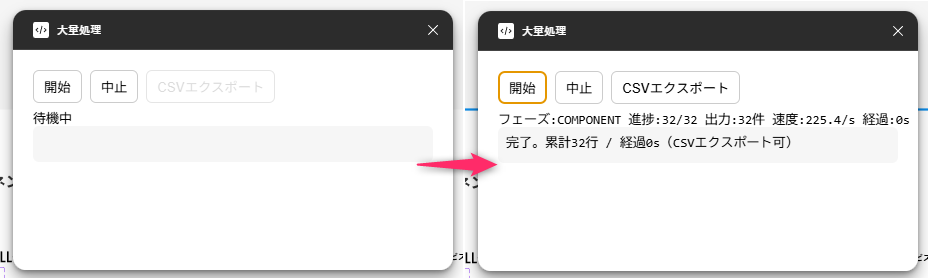
完成したプラグインの動作配下の通り。
- 「開始」を押すと処理が走り、UI に最新のレイヤー名が流れていく
- 数十万行でも処理が止まらず、途中で「中止」も可能
- 最後に「CSV エクスポート」を押すと BOM 付き UTF-8 の CSV が保存される
シンプルながら、大規模ドキュメントでも実用に耐える仕組みになりました。
以下3つの工夫をしています。
非同期バッチ処理
大きな配列を一気に処理せず、バッチに分割してループ末尾で await sleep(0)。
これにより、イベントループに制御が戻り UI の再描画やメッセージ処理が行えます。
処理中のUIは「最新1行のみ」表示
ログをべた書きすると DOM が巨大化して重くなります。
最新の処理対象だけを更新表示することで ほぼゼロコストで「動いている感」を出せます。
CSVはチャンク配列で構築
巨大な1本の文字列連結はメモリに負担。
小さな文字列ブロック(チャンク)を配列に push して最後にファイル化。
実際のプラグイン│コンポーネント及びコンポーネントセットの情報を出力
Figmaファイル内にあるすべてのコンポーネント情報を重複なく収集して、CSVに書き出すプラグイン